
Speed Up

Concurrency
Pre-emptive multitasking (threading)
The operating system decides when to switch tasks external to Python.
1
Cooperative multitasking (asyncio)
The tasks decide when to give up control.
1
Multiprocessing (multiprocessing)
The processes all run at the same time on different processors.
Many
When Is Concurrency Useful?
Concurrency can make a big difference for two types of problems. These are generally called CPU-bound and I/O-bound.
I/O-bound problems cause your program to slow down because it frequently must wait for input/output (I/O) from some external resource. They arise frequently when your program is working with things that are much slower than your CPU.
Examples of things that are slower than your CPU are legion, but your program thankfully does not interact with most of them. The slow things your program will interact with most frequently are the file system and network connections.
Let’s see what that looks like:
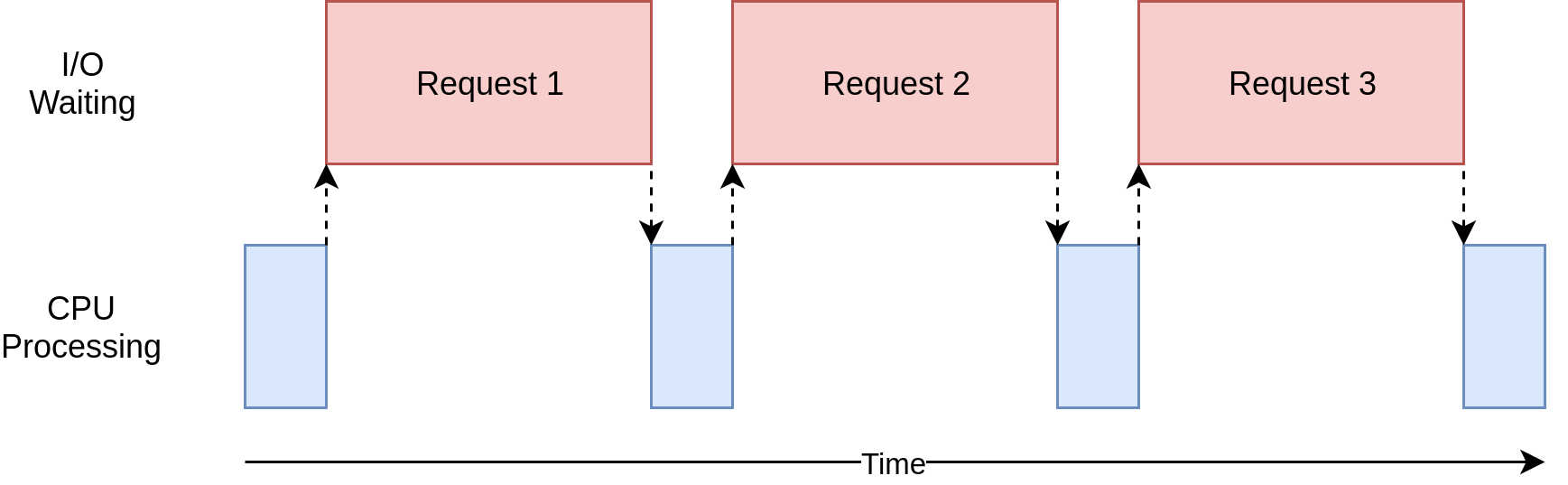
In the diagram above, the blue boxes show time when your program is doing work, and the red boxes are time spent waiting for an I/O operation to complete. This diagram is not to scale because requests on the internet can take several orders of magnitude longer than CPU instructions, so your program can end up spending most of its time waiting. This is what your browser is doing most of the time.
On the flip side, there are classes of programs that do significant computation without talking to the network or accessing a file. These are the CPU-bound programs, because the resource limiting the speed of your program is the CPU, not the network or the file system.
Here’s a corresponding diagram for a CPU-bound program:
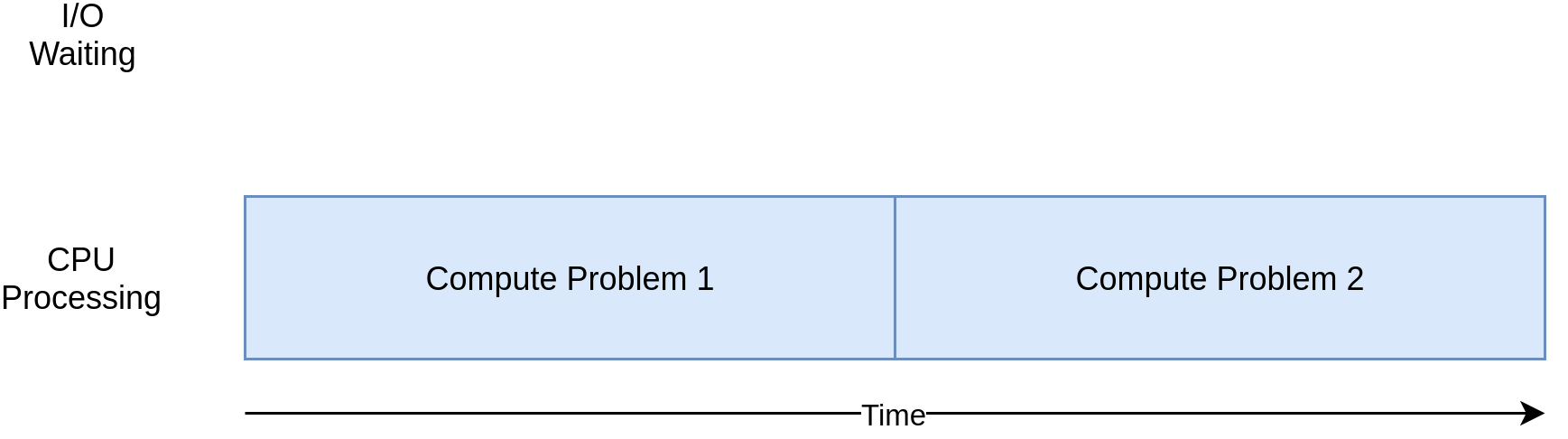
As you work through the examples in the following section, you’ll see that different forms of concurrency work better or worse with CPU-bound and I/O-bound programs. Adding concurrency to your program adds extra code and complications, so you’ll need to decide if the potential speed up is worth the extra effort. By the end of this article, you should have enough info to start making that decision.
Here’s a quick summary to clarify this concept:
Your program spends most of its time talking to a slow device, like a network connection, a hard drive, or a printer.
You program spends most of its time doing CPU operations.
Speeding it up involves overlapping the times spent waiting for these devices.
Speeding it up involves finding ways to do more computations in the same amount of time.
You’ll look at I/O-bound programs first. Then, you’ll get to see some code dealing with CPU-bound programs.
How to Speed Up an I/O-Bound Program
Let’s start by focusing on I/O-bound programs and a common problem: downloading content over the network. For our example, you will be downloading web pages from a few sites, but it really could be any network traffic. It’s just easier to visualize and set up with web pages.
Synchronous Version
We’ll start with a non-concurrent version of this task. Note that this program requires the requests module. You should run pip install requests before running it, probably using a virtualenv. This version does not use concurrency at all:
As you can see, this is a fairly short program. download_site() just downloads the contents from a URL and prints the size. One small thing to point out is that we’re using a Session object from requests.
It is possible to simply use get() from requests directly, but creating a Session object allows requests to do some fancy networking tricks and really speed things up.
download_all_sites() creates the Session and then walks through the list of sites, downloading each one in turn. Finally, it prints out how long this process took so you can have the satisfaction of seeing how much concurrency has helped us in the following examples.
The processing diagram for this program will look much like the I/O-bound diagram in the last section.
Note: Network traffic is dependent on many factors that can vary from second to second. I’ve seen the times of these tests double from one run to another due to network issues.
threading Version
threading VersionAs you probably guessed, writing a threaded program takes more effort. You might be surprised at how little extra effort it takes for simple cases, however. Here’s what the same program looks like with threading:
When you add threading, the overall structure is the same and you only needed to make a few changes. download_all_sites() changed from calling the function once per site to a more complex structure.
In this version, you’re creating a ThreadPoolExecutor, which seems like a complicated thing. Let’s break that down: ThreadPoolExecutor = Thread + Pool + Executor.
You already know about the Thread part. That’s just a train of thought we mentioned earlier. The Pool portion is where it starts to get interesting. This object is going to create a pool of threads, each of which can run concurrently. Finally, the Executor is the part that’s going to control how and when each of the threads in the pool will run. It will execute the request in the pool.
Helpfully, the standard library implements ThreadPoolExecutor as a context manager so you can use the with syntax to manage creating and freeing the pool of Threads.
Once you have a ThreadPoolExecutor, you can use its handy .map() method. This method runs the passed-in function on each of the sites in the list. The great part is that it automatically runs them concurrently using the pool of threads it is managing.
Those of you coming from other languages, or even Python 2, are probably wondering where the usual objects and functions are that manage the details you’re used to when dealing with threading, things like Thread.start(), Thread.join(), and Queue.
These are all still there, and you can use them to achieve fine-grained control of how your threads are run. But, starting with Python 3.2, the standard library added a higher-level abstraction called Executors that manage many of the details for you if you don’t need that fine-grained control.
The other interesting change in our example is that each thread needs to create its own requests.Session() object. When you’re looking at the documentation for requests, it’s not necessarily easy to tell, but reading this issue, it seems fairly clear that you need a separate Session for each thread.
This is one of the interesting and difficult issues with threading. Because the operating system is in control of when your task gets interrupted and another task starts, any data that is shared between the threads needs to be protected, or thread-safe. Unfortunately requests.Session() is not thread-safe.
There are several strategies for making data accesses thread-safe depending on what the data is and how you’re using it. One of them is to use thread-safe data structures like Queue from Python’s queue module.
These objects use low-level primitives like threading.Lock to ensure that only one thread can access a block of code or a bit of memory at the same time. You are using this strategy indirectly by way of the ThreadPoolExecutor object.
Another strategy to use here is something called thread local storage. threading.local() creates an object that looks like a global but is specific to each individual thread. In your example, this is done with thread_local and get_session():
Here’s what its execution timing diagram looks like:
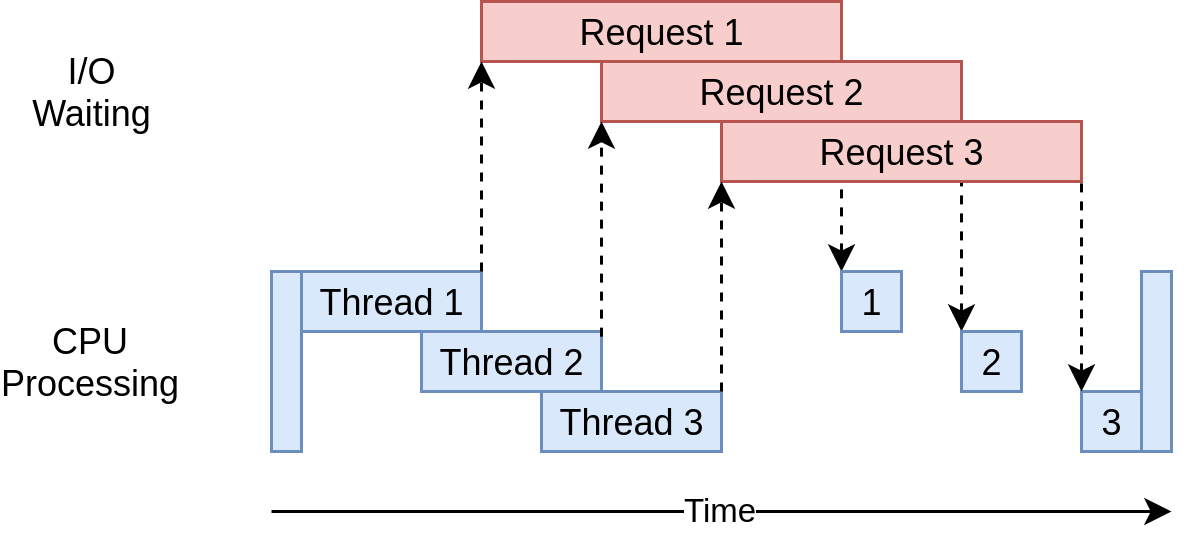
It uses multiple threads to have multiple open requests out to web sites at the same time, allowing your program to overlap the waiting times and get the final result faster! Yippee! That was the goal.
The Problems with the threading Version
threading VersionWell, as you can see from the example, it takes a little more code to make this happen, and you really have to give some thought to what data is shared between threads.
Threads can interact in ways that are subtle and hard to detect. These interactions can cause race conditions that frequently result in random, intermittent bugs that can be quite difficult to find. Those of you who are unfamiliar with the concept of race conditions might want to expand and read the section below.
asyncio Version
asyncio VersionThis will be a simplified version of asyncio. There are many details that are glossed over here, but it still conveys the idea of how it works.
The general concept of asyncio is that a single Python object, called the event loop, controls how and when each task gets run. The event loop is aware of each task and knows what state it’s in. In reality, there are many states that tasks could be in, but for now let’s imagine a simplified event loop that just has two states.
The ready state will indicate that a task has work to do and is ready to be run, and the waiting state means that the task is waiting for some external thing to finish, such as a network operation.
Your simplified event loop maintains two lists of tasks, one for each of these states. It selects one of the ready tasks and starts it back to running. That task is in complete control until it cooperatively hands the control back to the event loop.
When the running task gives control back to the event loop, the event loop places that task into either the ready or waiting list and then goes through each of the tasks in the waiting list to see if it has become ready by an I/O operation completing. It knows that the tasks in the ready list are still ready because it knows they haven’t run yet.
Once all of the tasks have been sorted into the right list again, the event loop picks the next task to run, and the process repeats. Your simplified event loop picks the task that has been waiting the longest and runs that. This process repeats until the event loop is finished.
An important point of asyncio is that the tasks never give up control without intentionally doing so. They never get interrupted in the middle of an operation. This allows us to share resources a bit more easily in asyncio than in threading. You don’t have to worry about making your code thread-safe.
That’s a high-level view of what’s happening with asyncio. If you want more detail, this StackOverflow answer provides some good details if you want to dig deeper.
async and await
Now let’s talk about two new keywords that were added to Python: async and await. In light of the discussion above, you can view await as the magic that allows the task to hand control back to the event loop. When your code awaits a function call, it’s a signal that the call is likely to be something that takes a while and that the task should give up control.
It’s easiest to think of async as a flag to Python telling it that the function about to be defined uses await. There are some cases where this is not strictly true, like asynchronous generators, but it holds for many cases and gives you a simple model while you’re getting started.
One exception to this that you’ll see in the next code is the async with statement, which creates a context manager from an object you would normally await. While the semantics are a little different, the idea is the same: to flag this context manager as something that can get swapped out.
As I’m sure you can imagine, there’s some complexity in managing the interaction between the event loop and the tasks. For developers starting out with asyncio, these details aren’t important, but you do need to remember that any function that calls await needs to be marked with async. You’ll get a syntax error otherwise.
This version is a bit more complex than the previous two. It has a similar structure, but there’s a bit more work setting up the tasks than there was creating the ThreadPoolExecutor. Let’s start at the top of the example.
download_site()
download_site() at the top is almost identical to the threading version with the exception of the async keyword on the function definition line and the async with keywords when you actually call session.get(). You’ll see later why Session can be passed in here rather than using thread-local storage.
download_all_sites()
download_all_sites() is where you will see the biggest change from the threading example.
You can share the session across all tasks, so the session is created here as a context manager. The tasks can share the session because they are all running on the same thread. There is no way one task could interrupt another while the session is in a bad state.
Inside that context manager, it creates a list of tasks using asyncio.ensure_future(), which also takes care of starting them. Once all the tasks are created, this function uses asyncio.gather() to keep the session context alive until all of the tasks have completed.
The threading code does something similar to this, but the details are conveniently handled in the ThreadPoolExecutor. There currently is not an AsyncioPoolExecutor class.
There is one small but important change buried in the details here, however. Remember how we talked about the number of threads to create? It wasn’t obvious in the threading example what the optimal number of threads was.
One of the cool advantages of asyncio is that it scales far better than threading. Each task takes far fewer resources and less time to create than a thread, so creating and running more of them works well. This example just creates a separate task for each site to download, which works out quite well.
__main__
Finally, the nature of asyncio means that you have to start up the event loop and tell it which tasks to run. The __main__ section at the bottom of the file contains the code to get_event_loop() and then run_until_complete(). If nothing else, they’ve done an excellent job in naming those functions.
If you’ve updated to Python 3.7, the Python core developers simplified this syntax for you. Instead of the asyncio.get_event_loop().run_until_complete() tongue-twister, you can just use asyncio.run().
The execution timing diagram looks quite similar to what’s happening in the threading example. It’s just that the I/O requests are all done by the same thread:
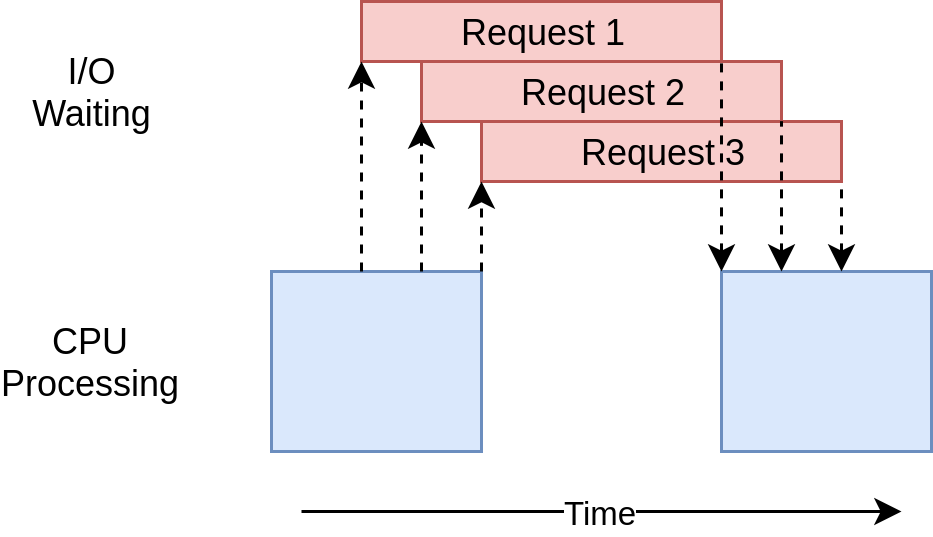
The lack of a nice wrapper like the ThreadPoolExecutor makes this code a bit more complex than the threading example. This is a case where you have to do a little extra work to get much better performance.
Also there’s a common argument that having to add async and await in the proper locations is an extra complication. To a small extent, that is true. The flip side of this argument is that it forces you to think about when a given task will get swapped out, which can help you create a better, faster, design.
The scaling issue also looms large here. Running the threading example above with a thread for each site is noticeably slower than running it with a handful of threads. Running the asyncio example with hundreds of tasks didn’t slow it down at all.
The Problems With the asyncio Version
There are a couple of issues with asyncio at this point. You need special async versions of libraries to gain the full advantage of asyncio. Had you just used requests for downloading the sites, it would have been much slower because requests is not designed to notify the event loop that it’s blocked. This issue is getting smaller and smaller as time goes on and more libraries embrace asyncio.
Another, more subtle, issue is that all of the advantages of cooperative multitasking get thrown away if one of the tasks doesn’t cooperate. A minor mistake in code can cause a task to run off and hold the processor for a long time, starving other tasks that need running. There is no way for the event loop to break in if a task does not hand control back to it.
With that in mind, let’s step up to a radically different approach to concurrency, multiprocessing.
How to Speed Up a CPU-Bound Program
Let’s shift gears here a little bit. The examples so far have all dealt with an I/O-bound problem. Now, you’ll look into a CPU-bound problem. As you saw, an I/O-bound problem spends most of its time waiting for external operations, like a network call, to complete. A CPU-bound problem, on the other hand, does few I/O operations, and its overall execution time is a factor of how fast it can process the required data.
For the purposes of our example, we’ll use a somewhat silly function to create something that takes a long time to run on the CPU. This function computes the sum of the squares of each number from 0 to the passed-in value:
You’ll be passing in large numbers, so this will take a while. Remember, this is just a placeholder for your code that actually does something useful and requires significant processing time, like computing the roots of equations or sorting a large data structure.
CPU-Bound Synchronous Version
Now let’s look at the non-concurrent version of the example:
This code calls cpu_bound() 20 times with a different large number each time. It does all of this on a single thread in a single process on a single CPU. The execution timing diagram looks like this:
CPU-Bound multiprocessing Version
multiprocessing VersionNow you’ve finally reached where multiprocessing really shines. Unlike the other concurrency libraries, multiprocessing is explicitly designed to share heavy CPU workloads across multiple CPUs. Here’s what its execution timing diagram looks like:
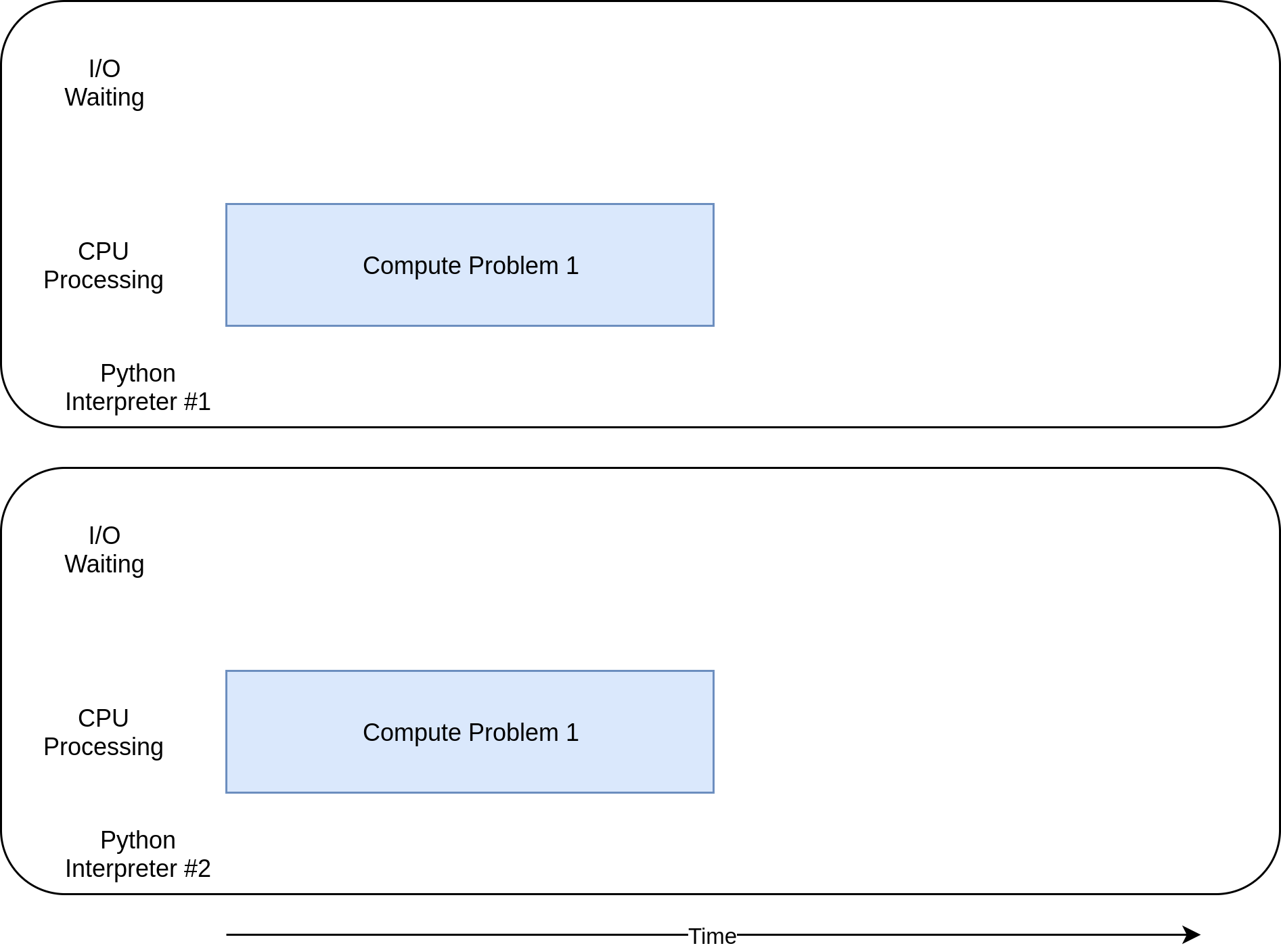
Here’s what the code looks like:
Little of this code had to change from the non-concurrent version. You had to import multiprocessing and then just change from looping through the numbers to creating a multiprocessing.Pool object and using its .map() method to send individual numbers to worker-processes as they become free.
This was just what you did for the I/O-bound multiprocessing code, but here you don’t need to worry about the Session object.
As mentioned above, the processes optional parameter to the multiprocessing.Pool() constructor deserves some attention. You can specify how many Process objects you want created and managed in the Pool. By default, it will determine how many CPUs are in your machine and create a process for each one. While this works great for our simple example, you might want to have a little more control in a production environment.
Also, as we mentioned in the first section about threading, the multiprocessing.Pool code is built upon building blocks like Queue and Semaphore that will be familiar to those of you who have done multithreaded and multiprocessing code in other languages.
When to Use Concurrency
You’ve covered a lot of ground here, so let’s review some of the key ideas and then discuss some decision points that will help you determine which, if any, concurrency module you want to use in your project.
The first step of this process is deciding if you should use a concurrency module. While the examples here make each of the libraries look pretty simple, concurrency always comes with extra complexity and can often result in bugs that are difficult to find.
Hold out on adding concurrency until you have a known performance issue and then determine which type of concurrency you need. As Donald Knuth has said, “Premature optimization is the root of all evil (or at least most of it) in programming.”
Once you’ve decided that you should optimize your program, figuring out if your program is CPU-bound or I/O-bound is a great next step. Remember that I/O-bound programs are those that spend most of their time waiting for something to happen while CPU-bound programs spend their time processing data or crunching numbers as fast as they can.
As you saw, CPU-bound problems only really gain from using multiprocessing. threading and asyncio did not help this type of problem at all.
For I/O-bound problems, there’s a general rule of thumb in the Python community: “Use asyncio when you can, threading when you must.” asyncio can provide the best speed up for this type of program, but sometimes you will require critical libraries that have not been ported to take advantage of asyncio. Remember that any task that doesn’t give up control to the event loop will block all of the other tasks.When to Use Concurrency
You’ve covered a lot of ground here, so let’s review some of the key ideas and then discuss some decision points that will help you determine which, if any, concurrency module you want to use in your project.
The first step of this process is deciding if you should use a concurrency module. While the examples here make each of the libraries look pretty simple, concurrency always comes with extra complexity and can often result in bugs that are difficult to find.
Hold out on adding concurrency until you have a known performance issue and then determine which type of concurrency you need. As Donald Knuth has said, “Premature optimization is the root of all evil (or at least most of it) in programming.”
Once you’ve decided that you should optimize your program, figuring out if your program is CPU-bound or I/O-bound is a great next step. Remember that I/O-bound programs are those that spend most of their time waiting for something to happen while CPU-bound programs spend their time processing data or crunching numbers as fast as they can.
As you saw, CPU-bound problems only really gain from using multiprocessing. threading and asyncio did not help this type of problem at all.
For I/O-bound problems, there’s a general rule of thumb in the Python community: “Use asyncio when you can, threading when you must.” asyncio can provide the best speed up for this type of program, but sometimes you will require critical libraries that have not been ported to take advantage of asyncio. Remember that any task that doesn’t give up control to the event loop will block all of the other tasks.
Last updated